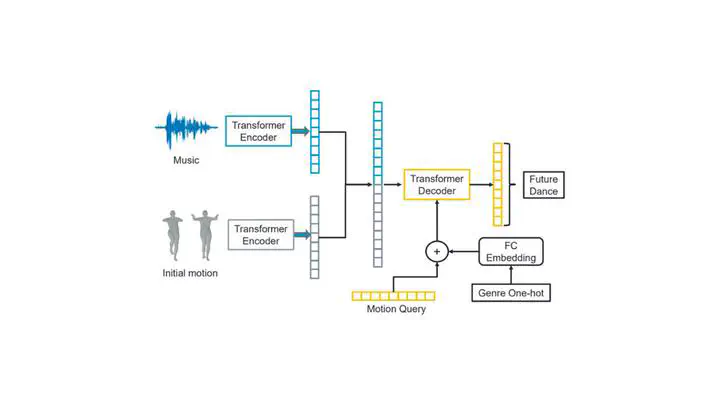
Dancing to music is an artistic behavior of humans, however, letting machines generate dances from music is still challenging. Most existing works have been made progress in tackling the problem of motion prediction conditioned by music, yet they rarely consider the importance of the musical genre. In this paper, we focus on generating long-term 3D dance from music with a specific genre. Specifically, we construct a pure transformer-based architecture to correlate motion features and music features. To utilize the genre information, we propose to embed the genre categories into the transformer decoder so that it can guide every frame. Moreover, different from previous inference schemes, we introduce the motion queries to output the dance sequence in parallel that significantly improves the efficiency. Extensive experiments on AIST++[1] dataset show that our model outperforms state-of-the-art methods with a much faster inference speed.