[IJCV'24]CDistNet: Perceiving Multi-domain Character Distance for Robust Text Recognition
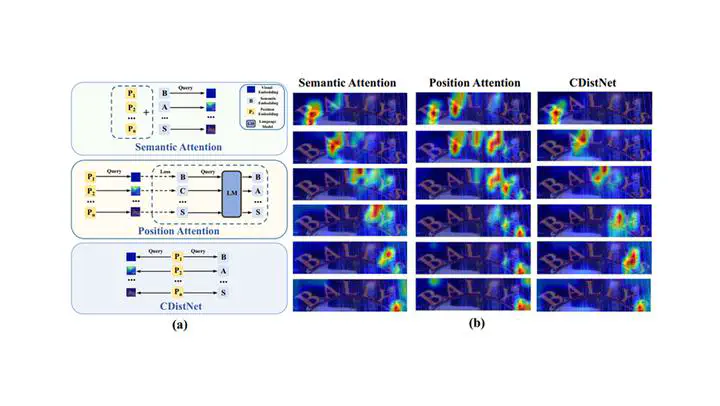
The transformer-based encoder-decoder framework is becoming popular in scene text recognition, largely because it naturally integrates recognition clues from both visual and semantic domains. However, recent studies show that the two kinds of clues are not always well registered and therefore, feature and character might be misaligned in difficult text (e.g., with a rare shape). As a result, constraints such as character position are introduced to alleviate this problem. Despite certain success, visual and semantic are still separately modeled and they are merely loosely associated. In this paper, we propose a novel module called multi-domain character distance perception (MDCDP) to establish a visually and semantically related position embedding. MDCDP uses the position embedding to query both visual and semantic features following the cross-attention mechanism. The two kinds of clues are fused into the position branch, generating a content-aware embedding that well perceives character spacing and orientation variants, character semantic affinities, and clues tying the two kinds of information. They are summarized as the multi-domain character distance. We develop CDistNet that stacks multiple MDCDPs to guide a gradually precise distance modeling. Thus, the feature-character alignment is well build even though various recognition difficulties are presented. We verify CDistNet on ten challenging public datasets and two series of augmented datasets created by ourselves. The experiments demonstrate that CDistNet performs highly competitively. It not only ranks top-tier in standard benchmarks, but also outperforms recent popular methods by obvious margins on real and augmented datasets presenting severe text deformation, poor linguistic support, and rare character layouts. In addition, the visualization shows that CDistNet achieves proper information utilization in both visual and semantic domains. Our code is available at https://github.com/simplify23/CDistNet.